








英伟达Rubin有望提前半年问世 AI算力新纪元即将到来?
- 房产
- 2024-12-06 17:48:02
- 28
有媒体援引知情人士透露的消息报道称,全球AI行业无比期待的英伟达(NVDA.US)下一代AI GPU架构——“Rubin”架构,可能将提前六个月,即2025年下半年正式发布。虽然Blackwell架构AI GPU仍未大规模发货且被爆出面临散热问题,但英伟达似乎坚定加速其AI GPU发展路线图,面对AMD、亚马逊以及博通等AI芯片竞争对手发起的猛烈攻势,这家“绿色巨人”试图强化它在数据中心AI芯片市场的绝对主导地位。英伟达当前在该市场堪称“垄断”,占据80%-90%份额。
尽管 Blackwell 架构AI GPU可能明年第一季度才能在台积电、鸿海、纬颖以及纬创等众多核心供应商齐心协力之下实现大规模量产,但是随着谷歌、亚马逊等云巨头自研AI芯片浪潮席卷而来,英伟达现在比以往任何时候都更加致力于在数据中心AI芯片市场中保持主导地位。对于英伟达股东们来说,他们也需要新的催化剂推动英伟达股价向200美元发起冲击。
包括OpenAI以及微软在内的众多AI行业领军者,以及摩根士丹利等华尔街投行们已经开始讨论英伟达下一代架构Rubin的性能将如何强大。一些产业链分析人士认为依托共同封装光学(CPO)技术以及HBM4,加之台积电3nm以及下一代CoWoS先进封装所打造的Rubin架构AI GPU堪称“史无前例的性能”,有可能开启AI算力全新纪元,竞争对手们可能需要耗费数年时间来进行追赶。
根据产业链知情人士透露的消息,英伟达Rubin架构的产品线原定于2026年上半年推出,现已要求供应链开启提前测试工作,力争提前至2025年下半年正式推出。由于OpenAI、Anthropic、xAI以及Meta等人工智能、云计算以及互联网大厂们对于AI训练/推理算力几乎无止境的“井喷式需求”,迫使英伟达以更快速度推出性能更高、存储容量更庞大、推理效率更强大且更加节能的下一代AI GPU的研发进程。这家绿色巨人试图加快不同AI GPU架构之间的更新节奏。
虽然英伟达官方未进行回复,但是从存储芯片制造巨头SK海力士(SK Hynix)上月初透露的可能提前生产交付HBM4的消息来看,关于Rubin消息的真实性非常高。HBM通过3D堆叠存储技术,将堆叠的多个DRAM芯片全面连接在一起,通过微细的Through-Silicon Vias(TSVs)进行数据传输,从而实现高速高带宽的数据传输,使得AI大模型能够24小时不间断地更高效地运行。
据了解,SK集团董事长崔泰源在11月初接受采访时表示,英伟达首席执行官黄仁勋要求SK海力士提前六个月推出其下一代高带宽存储产品HBM4。作为英伟达H100/H200以及近期开始生产的Blackwell AI GPU的最核心HBM存储系统供应商,SK海力士一直在引领全球存储芯片产能竞赛,以满足英伟达、AMD以及谷歌等大客户们满足对HBM存储系统的爆炸性需求以及其他企业对于数据中心SSD等企业级存储产品的需求,这些存储级的芯片产品对于处理海量数据以训练出愈发强大的人工智能大模型以及需求剧增的云端AI推理算力而言堪称核心硬件。
在关于Rubin的最新消息出炉之前,英伟达目前正处于“一年一代际”的AI GPU架构更新节奏中,这意味着该公司每年都会发布新一代架构的数据中心AI GPU产品,这就是为什么Ampere、Hopper和Blackwell架构之间都有长达一年的间隔;然而,对于Rubin,这种情况可能彻底改变。
知情人士并未提及英伟达为何要提前推出Rubin的具体原因,只是将其归类为一项商业举措。然而,如果我们从供应链角度来看,Rubin预计将采用台积电的3nm工艺,以及存储领域具有划时代意义的HBM4,加上可能是全球首个采取CPO+硅晶圆封装的数据中心级别AI芯片,这些最关键的核心环节要么已经开始准备——比如台积电3nm准备就绪、HBM4可能已经处于测试环节,要么已确定能够实现量产,比如CPO封装。因此,鉴于英伟达可能已经为Rubin配备了所有“工具”,黄仁勋可能认为在2026年发布Rubin不太合适。
根据英伟达在GTC披露的产品路线,Blackwell升级版——“Blackwell Ultra”产品线,即“B300”系列的首次亮相,英伟达计划在2025年中期发布该系列。因此,我们可能将看到Blackwell Ultra与Rubin发布的时间点非常靠近。目前发布策略尚不明确,但Wccftech以及The Verge的一些专业人士表示,英伟达可能将重点放在Rubin架构,将B300系列视为过渡产品。按照英伟达惯例,预计该公司很快会将发布更多更新,可能是在2025年国际消费电子展(CES)前后。
Blackwell已经非常强大! 但Rubin,或将开启AI算力新纪元
Blackwell架构AI GPU系列产品,毫无疑问是当前AI算力基础设施领域的“性能天花板”。在Blackwell出炉前,Hopper也一度被视为算力天花板,而在CPO以及3nm、相比于HBM3E性能大幅增强的HBM4,加之下一代CoWoS加持下,暂不考虑Rubin本身的基础架构升级,Rubin芯片性能可能已经强到无法想象。对于英伟达业绩预期来说,Rubin或将推动华尔街大幅上调2026年基本面展望。
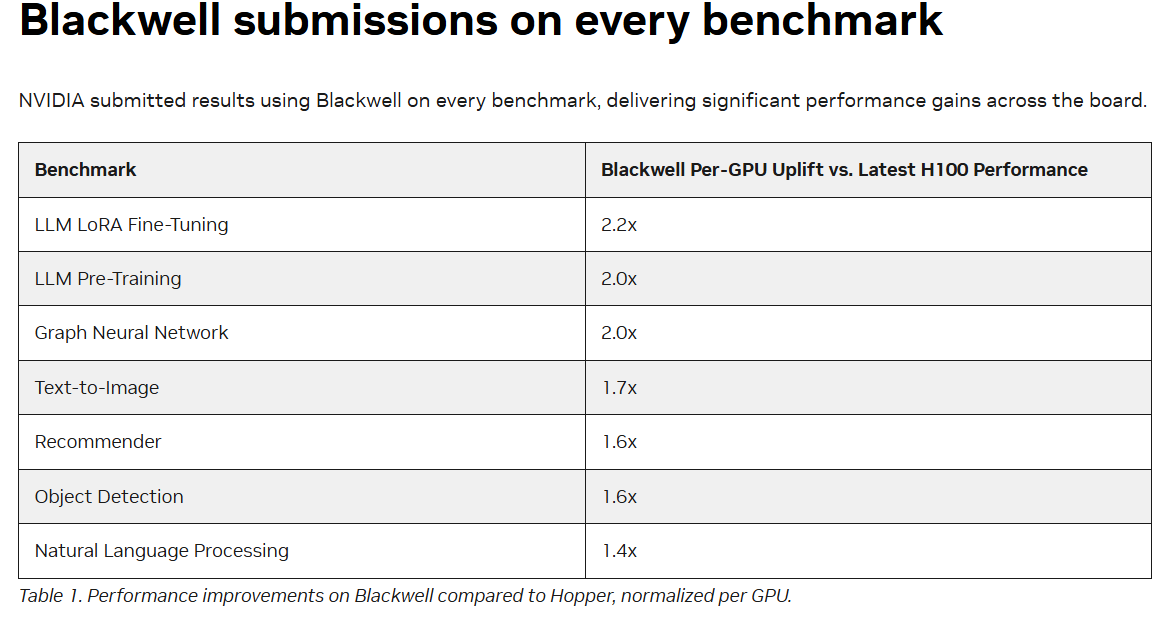
作为基准对标,Blackwell性能已经比Hopper强劲得多,在MLPerf Training基准测试中,Blackwell在GPT-3预训练任务中每GPU性能比Hopper大幅提升2倍。这意味着在相同数量的GPU下,使用Blackwell可以更快地完成模型训练。对于Llama 2 70B模型的LoRA微调任务,Blackwell每GPU性能比Hopper提升2.2倍,这表明Blackwell在处理特定高负载AI任务时具备更高的效率。MLPerf Training v4.1 中,图形神经网络以及Text-to-Image基准测试方面,Blackwell每GPU性能比Hopper分别提升2倍以及1.7倍。
根据知情人士披露的消息,以及摩根士丹利调研后的产业链报告,Rubin架构AI GPU 计划采用台积电最新3nm 技术、CPO 封装以及 HBM4;Rubin的芯片尺寸或将是Blackwell的近两倍,Rubin可能包含四个核心计算芯片,是Blackwell架构的两倍。知情人士透露,3nm Rubin 架构预计将在2025年下半年进入流片阶段,较英伟达之前预期时间提前半年左右。
根据目前披露出的消息来看,Rubin架构的最大亮点无疑是共同封装光学(CPO)。Hopper与Blackwell互连技术更多仍依赖改进之后的 NVLink 以及芯片互连技术,而不是直接通过光学方式进行数据传输。
Rubin大概率是全球首个采取CPO+硅晶圆先进封装的数据中心级别AI芯片,CPO所带来的数据传输效率以及能耗效率,或将相比于NVLink 呈现出指数级飞跃。在CPO封装体系中,光学元器件(如激光器、光调制器、光纤和光探测器)直接与核心计算芯片(如GPU或CPU)封装在一起,而不是将光学器件单独放置在芯片外部,这些光学元件的作用是传递光信号,替代传统的电信号传输方式,进行芯片间数据的高速传输,大幅减少电子数据从芯片到光学接口之间的信号损耗,指数级提高数据吞吐量的同时还能大幅降低功耗。
通过光信号的高速传输,CPO能提供比传统电信号传输更高的数据带宽,这对于人工智能、大数据以及高性能计算(HPC)应用中,尤其是在需要大规模并行计算时至关重要。因此CPO封装被认为是英伟达Rubin架构AI GPU的核心亮点,它将为下一代AI和高性能计算提供极高的带宽、低延迟和大幅提升的能效。在业内人士看来,由于CPO技术能够更大程度解决数据传输速率和功耗问题,它的应用将进一步推动英伟达在数据中心AI芯片市场的领先地位。
下一篇:LPG:跌超3%还能跌吗?
相关文章
热门文章

狂飙的蔚来怎么翻车了
2024-11-29美国小伙眼中的北京,公元3000年的感觉
2024-12-02邱淑贞一家三口首度亮相尼泊尔
2024-11-28白小姐今晚特马期期准六,停业精选解释落实_WP6.93.94V39.88.80
2024-12-02
联合国人权专家表示,海地的不安全局势正在恶化,因为帮派占据了更多的领土
2024-12-03男子婚礼前健身过度入院
2024-11-29管家婆精准资料大全免费,打秋风精选答案落实_iPad851.3V73.60.17
2024-12-02突发新闻:刘易斯·汉密尔顿遭遇美国大奖赛排位赛噩梦,奥斯汀F1赛道一片寂静
2024-11-30
有话要说...